While working on an API today I realized the JMSSerializer does not support neither DateTimeInteface nor DateTimeImmutable. I am going to walk you through the necessary steps to serialize DateTimeImmutable objects using JMSSerializer.
Building an own handler requires not much code. The only problem is that documentation is scattered to many places and sometimes hard to find. I’m working on a full-stack Symfony 2.8 with JMSSerializerBundle installed. So make sure you are on the same page before starting.
That’s it. Now your DateTime and DateTimeImmutable objects should be serialized to string similar to 2016-09-28T12:54:07+00:00. If you encounter problems or have further questions find me on Twitter.
Good documentation is the key to utilize an API. But it is difficult to keep documentation and development of you API in sync. Differences between implementation and documentation are often hard to spot. Learn how you can use Swagger to document you API first and profit by testing your implementation against your documentation and vice versa. No duplication needed!
Swagger Logo
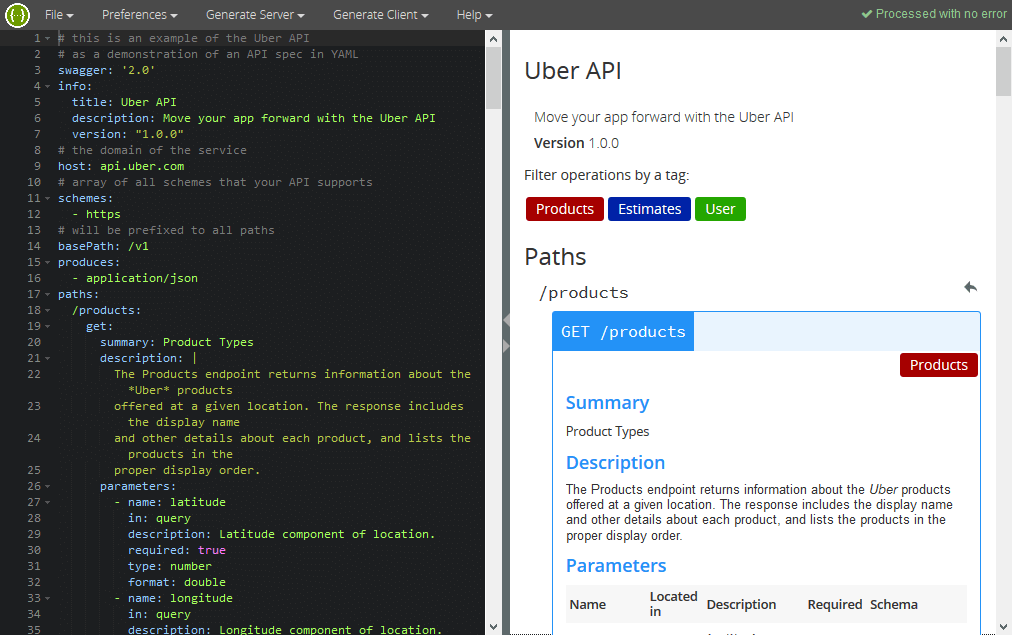
I recently started planning a new RESTful API for my company. After some initial discussion on the scope and which API endpoints are needed I set out to write the specification in Swagger 2.0. This provided for a good starting point to the further refinement discussion. It also proved very useful to exchange information with our frontend developers in charge of implementing the first API consumer.
Swagger Editor
At first we started using Swagger Editor and YAML as format (because it is the lingua franca of Swagger Editor). Swagger Editor is a great tool to get started using Swagger. It runs directly in your browser, validates your YAML input and renders a beautiful interactive web interface. We were sending the swagger.yaml file around and I was maintaining the authoritative version of the file. This worked well for the start but it was obvious to us that we needed a tighter coupling to the application and track the file in sync with the implementation.
I had worked with NelmioApiDocBundle before to integrate Swagger with a Symfony application and it is a wonderful tool to document your existing API code. But as NelmioApiDocBundle generates the Swagger file from the annotated source code the source must exist prior to the documentation. This did not match our desired workflow. What’s more, the future of NelmioApiDocBundle seems to be a bit uncertain as the William Durand, the current maintainer, thinks of deprecating the bundle1.
I am thinking about slowly deprecating #NelmioApiDocBundle (feature-freeze first, then EOL). Thoughts?
As I only needed a view component for my Swagger file and had no need for the annotation stuff SwaggerUIBundle was good enough for the job. That made it necessary to convert my Swagger file from YAML to JSON, but that’s no big deal as the Swagger Editor has an export option for JSON. For the Bundle configuration take a look at the installation instructions for static JSON files. This is what my routing configuration looked like:
As I started implementing the first endpoints I also created the first Test Cases in parallel with development. And because I am lazy, I did not want to repeat myself and write the same definitions I already had in my Swagger file for my test assertions again. So I was looking for a way to reuse my Swagger specification in my test’s assertion.
Swagger UI
The model definitions of Swagger 2.0 are valid JSON Schema which aims to be similar as XSD or DTD for XML. And fortunately there is already a library for PHPUnit JSON Schema Assertions. The only problem was I had a single huge Swagger file and I found no way to validate my API response only against a part of the big Swagger definition. JSON Schema allows splitting up the definition into multiple files and referencing these files using $ref. For more information about Referencing take a look at the OpenAPI Guidelines for Referencing, How to split a Swagger spec into smaller files and Structuring a complex schema.
After splitting up the file SwaggerUIBundle did not work anymore because it has problems handling and resolving the JSON references correctly. But that’s not a problem a of SwaggerUI, it’s only a problem of the bundle. As workaround I moved my Swagger files to src/AppBundle/Resources/public/swagger so that Symfony takes care of populating my files in the web root and I adjusted the SwaggerUIBundle configuration to just take that static entry point.
If your JSON Schema uses several nesting levels you might need to adjust the $maxDepth of the RefResover (the component that resolves your $ref).
JsonSchema\RefResolver::$maxDepth=10;
This got me what I want. Whenever there is a change either in the documentation or the implementation it will break the tests and the developer has to make sure both align. This ensures that the documentation is updated on code change and is maintained and also provides easy tests for new endpoints as a bonus!
If you are using NelmioApiDocBundle and looking for alternatives, read this insightful article by David Buchman who coverted his NemlioApiDocBundle annotations to swagger-php annotations. ↩
This article was originally published at flagbit.de.
If you write lots of Console Commands in your Symfony application you sure want
to know more about their memory and time consumption. To collect the necessary
data you can make use of the Stopwatch
Component.
Wir führen unsere Unittests automatisiert beim Push auf das Git-Repository mit Jenkins aus. Bevor Änderungen auf dem Livesystem eingespielt werden dürfen ist ein “grüner Build” zwingend erforderlich. Bei größeren Projekten kam es bei der Ausführung von PHPUnit immer wieder zu Segmentation Faults mit exec returned: 139. Beim zweiten Anlauf funktionierte es dann meistens, aber es ist natürlich sehr lästig, weil dadurch bei einer Dauer von ca. 30 Minuten für einen vollständigen Build das Livestellen unnötig verzögert wird.
In phpunit you can do:
phpunit -d zend.enable_gc=0
Bei meinem ersten Versuch mit deaktivierter Garbage
Collection wurde natürlich das
memory_limit
überschritten. Eine Erhöhung auf 1,5GB löste zwar das Problem mit dem Limit,
jedoch brach daraufhin PHPUnit bei der Erzeugung des Clover-Reports
unvermittelt ab. Diesmal mit exec returned: 143. Google förderte leider kaum
brauchbare Ergebnisse zutage, jedoch lag die Vermutung nahe, dass es eben nicht
so optimal ist, die Garbage Collection für den kompletten PHPUnit-Lauf zu
deaktivieren.
Daraufhin haben wir eine eigene Zwischenklasse zwischen
PHPUnit_Framework_TestCase und unsere TestCases geschoben, in der die Garbage
Collection explizit gesteuert wird. Vor jedem Test wird die GC explizit mit gc_collect_cycles()
aufgerufen, anschließend für den Test deaktiviert und nach dem Test wieder
aktiviert:
Jeder Entwickler weiß, dass Diagramme oft helfen, über Inhalte zu sprechen.
Aber Lust sich in eines der grafischen Tools einzuarbeiten, hat man dann meist
doch nicht. Jedes verwendet einen anderen Standard und andere Konventionen, um
im Wiki darüber zu reden muss man das Diagramm mühsam als Bild exportieren und
eigentlich schreibt man ja am liebsten Code und klickt eher ungern.
Wir haben bei bisher vereinzelt Visual Paradigm UML eingesetzt. An sich ist das
Tool ganz brauchbar, vor allem wenn man Java entwickelt und das
Round-Trip-Engineering funktioniert. Wir arbeiten aber eher punktuell mit
UML-Diagrammen, d.h. meistens möchte man nur eine kleine Änderung machen oder
nur ein Fragment der gesamten Software abbilden. Daher lohnt es sich nicht für
jeden Entwickler eine Lizenz zu kaufen und wir haben deshalb eine Floating
License. Funktioniert auch prima, solange man im Büro (und damit im
Firmennetzwerk) ist. Aber sobald man unterwegs oder beim Kunden vor Ort ist
kann man nicht “mal eben” das Diagramm anpassen. Außerdem braucht die Software
relativ lang zum Starten, was gerade bei kleinen Änderungen auch lästig sein
kann (und offen lassen will man das Programm ja auch nicht, weil man dann die
Floating License blockiert).
Vor ein paar Wochen bin ich auf der Suche nach einem UML-Plugin für DokuWiki
über PlantUML gestolpert. Mit PlantUML lassen sich (mit Hilfe von Graphviz) aus
Text UML-Diagramme erstellen. So lässt sich folgendes
Authentifzierungs-Sequenzdiagramm einfach mit ein paar Zeilen Code erzeugen:
Sequenzdiagramm Authentication
@startuml
Alice -> Bob: Authentication Request
Bob --> Alice: Authentication Response
@enduml
Sequenzdiagramm Authentication
Neben Sequenzdiagrammen werden auch Use-Case-Diagramme, Klassendiagramme,
Komponentendiagramme, Zustandsdiagramme und Objektdiagramme unterstützt.
Außerdem gibt es Integrationen für MediaWiki, Redmine, Confluence, Trac,
TinyMCE, Eclipse, NetBeans, Intellij (auch PHPStrom), Word, OpenOffice LaTeX,
Doxygen, Sphinx und vieles mehr. Dadurch sind sowohl die Diagramme als auch das
Syntax-Wissen portabel und vielseitig einsetzbar. Ich habe als nächstes direkt
das Plugin für unser Confluence installiert und auch Sphinx (was wir gerade für
Dokumentationen testen) funktioniert prima.
Als ich mir heute mit PHP Autoload
(phpab) meine Autoload-Datei neu
generieren ließ, war ich bass erstaunt. Statt der üblichen 700 Klassen waren
plötzlich nur noch 15 Dateien enthalten.
Nach ein bisschen Debuggen kam ich dann recht schnell dahinter, dass die
Ursache in der Klasse \TheSeer\DirectoryScanner\PHPFilterIterator liegt:
Dort wird nämlich der Mime-Type der Datei überprüft und nur Dateien mit
Mime-Type text/x-php werden überhaupt nach Klassen durchsucht. Meine Dateien
haben lustigerweise aber zum Großteil text/x-c++ – zumindest wenn ich mir das
unter Windows anschaue. In meiner virtuellen Maschine haben die selben Dateien,
die dann über vboxsf eingebunden sind, den korrekten Mime-Type.
Klar – ich kann das erstmal umgehen, indem im PHPFilterIterator ein return
true einbaue; aber schön ist anders. Hat jemand einen Tipp wie man den
Mime-Type einer Datei ändern kann oder noch interessanter: wie das Problem
überhaupt entstanden sein könnte? Da es in der Linux-VM korrekt angezeigt wird
ist ja vermutlich irgendwas an meinem Windows kaputtkonfiguriert…
Jeder der mit Datumswerten gearbeitet hat, weiß (oder sollte zumindest) um die
kleinen und großen Untiefen wie Zeitzonen, Zeitumstellung und Schaltjahre die
es dabei zu umschiffen gilt. Neben der seit PHP 5.2 verfügbaren
DateTime-Klasse gibt es im Zend
Framework die ältere
Zend_Date-Komponente. Mit
beiden lässt sich die Handhabung von Datumswerten in einer Applikation
vereinfachen und vereinheitlichen:
Bei der Verwendung der
Formatcodes
ist darauf zu achten “yyyy” und das ähnlich aussehende “YYYY” keinesfalls zu
verwechseln! Beide geben zwar das Jahr aus, aber mit einem kleinen, aber
gewichtigen Unterschied.
Intern verwendet Zend_Date zur Formatierung die
date-Funktion und konvertiert die
Zend_Date-Formatcodes entsprechend. Während “yyyy” zu “Y” konvertiert wird und
das erwartete Ergebnis liefert, wird “YYYY” zu “o” umgewandelt. Und “o” hat
folgende Bedeutung:
ISO-8601 year number. This has the same value as Y, except that if the ISO week
number (W) belongs to the previous or next year, that year is used instead.
(added in PHP 5.1.0)
– php.net
Da die erste Tage im Jahr 2011 noch zur letzten Kalenderwoche des Jahres 2010
gehören, wird gemäß ISO 8601 das Jahr
2010 ausgegeben. Und das dürfte in den seltesten Fällen das sein, was man
möchte…
Vor einigen Tagen war es soweit: PHP 5.4 wurde veröffentlicht. Die Anzahl der Änderungen sind, im Vergleich mit PHP 5.3, überschaubar, aber dennoch sollte man sie kennen. Die wichtigsten Änderungen kurz zusammengefasst:
Manchmal sucht man Fehler, die man wieder und wieder überliest, weil man die
falschen Annahmen getroffen hat und der Code oberflächlich richtig aussieht.
Erfahrungsgemäß gibt es dann ein paar “übliche Verdächtige”, die man sich
genauer anschaut. Zuweisungen im
if-Statement,
Vergleiche ohne Typprüfung, empty() und
isset() sind dabei immer heiße Kandidaten.
Wenn man die Handbuch-Seite zu isset() durchliest, klingt es, als wäre es
problemlos möglich auch die Existenz von Array-Keys zu prüfen. Sogar ein
schönes Beispiel gibt es dazu:
<?php$a=array('test'=>1,'hello'=>NULL,'pie'=>array('a'=>'apple'),);var_dump(isset($a['test']));// TRUEvar_dump(isset($a['foo']));// FALSEvar_dump(isset($a['hello']));// FALSE// The key 'hello' equals NULL so is considered unset// If you want to check for NULL key values then try: var_dump(array_key_exists('hello',$a));// TRUE// Checking deeper array valuesvar_dump(isset($a['pie']['a']));// TRUEvar_dump(isset($a['pie']['b']));// FALSEvar_dump(isset($a['cake']['a']['b']));// FALSE
Doch ganz so einfach ist es leider nicht. Interessant ist hier vor allem die
letzte Zeile. Erst auf den zweiten Blick fällt auf, dass als erster Schlüssel
“cake” statt “pie” verwendet wird. Und das ist der einzige Grund dafür, dass
FALSE zurückgegeben wird. Ändert man nämlich den ersten Schlüssel auf “pie”,
wird TRUE zurückgegeben, auch wenn der dritte Key nicht existiert:
Wichtig ist hier auch, dass man zuerst das isset() und danach das
is_array() schreibt, sonst bekommt man einen Undefined-index-Fehler, wenn der
Schlüssel komplett nicht vorhanden ist. Ein alleinstehendes isset() in
Verbindung mit einem Array sollte einen also immer misstrauisch machen. Je nach
Fall sollte ein is_array() ergänzt oder ein
array_key_exists()
bevorzugt werden.
Bei der Fehlersuche bieten einem die Application-Logs oftmals einen guten Einstiegspunkt. Doch die Suche darin kann zum Teil recht mühsam sein. Vor allem wenn man nicht nach der Fehlermeldung selbst suchen will, sondern zum Beispiel alle Fehler haben will, die einen bestimmten Methodenaufruf im Stacktrace haben. Und dann wollte ich auch nicht nur die Zeile haben, sondern den ganzen Log-Eintrag, inklusive Message und komplettem Stacktrace.
Ich habe mir dafür ein kleines PHP-Skript geschrieben. Vielleicht findet es ja sonst jemand nützlich:
Hier war in den letzten Monaten mal wieder Beitrags-Flaute, was vor allem daran liegt, dass ich seit etwa vier Monaten an einem Zend-Framework-Projekt entwickle und nur noch sporadisch mit Magento zu tun habe. Deshalb geht es auch heute nicht um Magento direkt, sondern um die Cache-Komponente von Zend Framework. Magento-Entwickler müssen jetz nicht gleich aufhören zu lesen, denn Zend_Cache bildet auch die Basis für den Cache in Magento.
Die nützliche Firefox-Extension zum JavaScript debugging Firebug dürfte inzwischen weithin bekannt sein. Firebug selbst ist auch wieder erweiterbar und gestern bin ich auf eine Firebug-Extension für PHP mit dem sinnigen Namen FirePHP gestoßen. Damit lassen sich Logging- oder Debug-Ausgaben direkt auf die Firebug-Konsole ausgeben. Damit die Kommunikation (über eigene HTTP-Header-Zeilen) funktioniert, muss auf dem Server allerdings das Output-Buffering aktivert werden. Eine Anleitung gibt’s auf der FirePHP-Homepage.
Wen, wie mich, auch schon immer gestört hat, dass man Arrays mit PHPDoc nicht "typisieren" kann, und man somit für die Array-Elemente keine Code-Vervollständigung mehr hat, für den habe ich gerade einen praktischen Workaround gefunden:
<?phpforeach($foosas$foo){/* @var $foo Foo */$foo->bar();// <-- this will generate code completion}?>
Ebenfalls schon etwas her, aber noch nicht soo lange (letzte Woche), ist meine bestandene PHP5-Zertifizierung. Seitdem darf ich mich offiziell mit dem Titel Zend Certified Engineer schmücken.